Xception: Deep Learning with Depthwise Separable Convolutions
We present an interpretation of Inception modules in convolutional neural networks as being an intermediate step in-between regular convolution and the depthwise separable convolution operation (a depthwise convolution followed by a pointwise convolution).
arxiv.org
0. 핵심 요약
Inception에서 기존에 사용되었던 regular convolution을 depthwise convolution으로 대체한 모델인 Xception 제안
이는 Inception V3보다 파라미터의 수가 더 적어 효율적이면서 동시에 성능도 뛰어남
1. BackGround
- JFT Dataset
해당 논문에서는 ImageNet 데이터와 함께 JFT 데이터셋을 사용
해당 데이터는 Google에서 생성한 데이터로써, 약 350 million개의 이미지가 존재하고 약 17000개의 클래스가 존재
하지만 해당 데이터는 오픈 소스로 공개된 것이 아닌 Google 사 내부에서만 사용되는 것으로 추정
- Inception에 대한 해석
Inception의 모듈은 쉽게 다음과 같이 구성되어 있음

여기에서 Avg Pool을 제외하고 3 x 3 convolution을 단순화 하여 표현하면 다음과 같이 표현할 수 있다

이 그림을 보면 1 x 1 convolution이 먼저 수행되고 그 이후에 3 x 3 convolution이 수행되는 모듈이 여러 번 사용되는 것처럼 보인다
따라서 이 그림을 더욱 단순하게 그리면 다음과 같이 표현할 수 있다

이 그림이 표현하고자 하는 것은 다음과 같다
우선 Inception은 다음과 같은 가정 하에 모델이 구성되었다
' cross-channel correlation과 spatial correlation은 서로 완전히 분리될 수 있다'
즉, 1 x 1 convolution을 사용하여 먼저 cross-channel correlation을 파악한 뒤, 여러 개의 3 x 3 convolution을 사용하여 spatial correlation을 파악하고자 한 것이다
이때 논문의 저자는 2가지 의문을 제시한다
1. 3 x 3을 여러 개 사용하는 것이 과연 효과적인가?
2. cross-channel correlation과 spatial correlation을 완벽하게 분리하는 것이 가능할까?
이러한 의문을 해결하기 위해 논문의 저자는 위의 그림을 극단적으로 표현해보았다
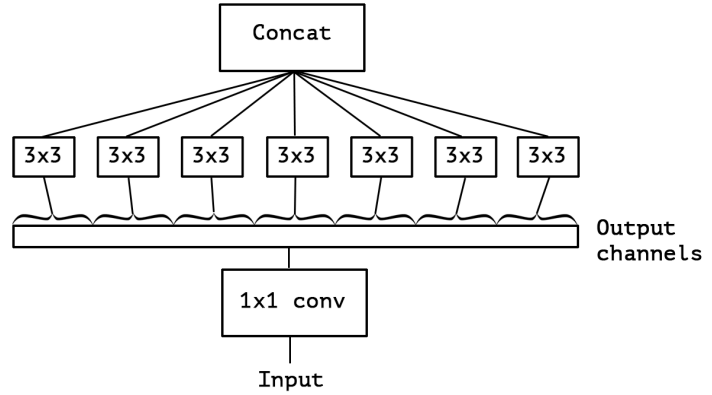
3 x 3 convolution을 매우 많이 키워서 1 x 1 convolution의 output 1개마다 3 x 3 convolution을 배치한 것
이를 보고 논문의 저자는 어떠한 한 convolution과 유사하다는 것을 발견
그것은 바로 'depthwise separable convolution' 이며, 여기에서 inception의 아이디어를 더욱 발전시킬 수 있다 판단
2. 논문 핵심 내용
- Depthwise Separable Convolution
Depthwise Separable Convolution은 기존의 convolution을 2 단계로 분리한 것이라고 이해하면 편하다
이는 총 2 단계를 가지고 있는데 각 단계는 다음과 같다
1. Depthwise Convolution
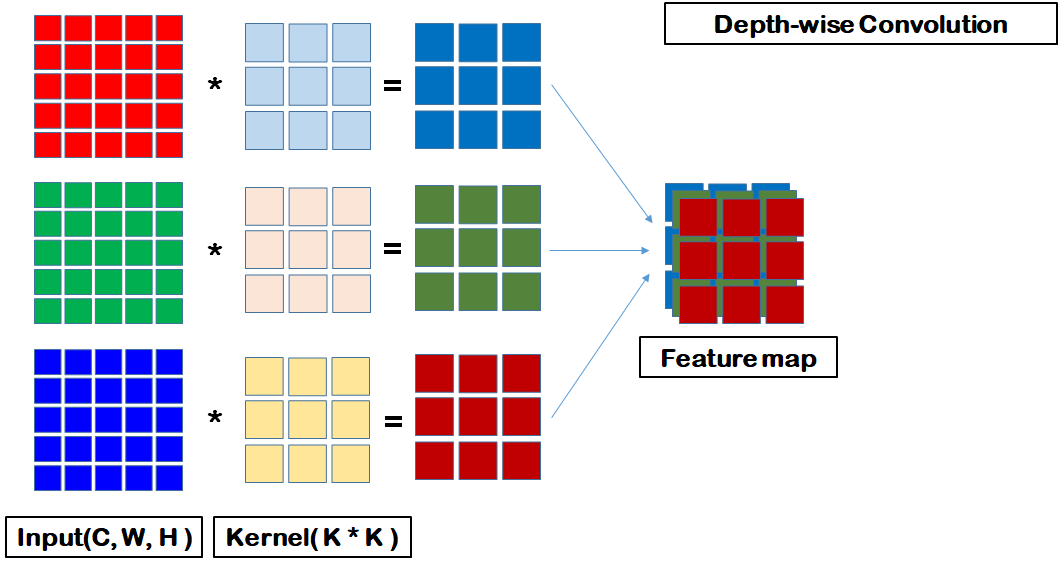
위 이미지를 보게 되면, 총 3개의 channel을 가진 input이 존재
이때, 각 channel마다 서로 다른 filter를 사용한다
그런 뒤 3개의 출력 값을 concat 하여 하나의 output을 생성
이는 channel 별 특성을 파악하기 위한 과정, 즉 spatial correlation을 파악하는 과정
2. Pointwise Convolution

위 그림을 보면, 1 x 1 convolution을 통해 서로 다른 channel에서 같은 위치에 있는 값들을 하나로 모아준다
이는, cross-channel correlation을 파악하기 위함
즉, 최종적으로 depthwise separable convolution을 그림으로 표현하면 다음과 같다

- Inception vs Depthwise Separable Convolution
논문의 저자는 Inception과 Depthwise separable convolution이 매우 유사하다는 것을 발견
바로 두 모델 모두 cross-channel correlation과 spatial correlation을 분리하고자 한 것
이때 두 모델의 차이점에는 총 2가지가 존재
1. convolution 적용 순서
2. 비선형 함수 유무
→ Inception은 1 x 1 convolution과 3 x 3 convolution 사이에 비선형 함수가 존재하지만 depthwise separable convolution은 존재하지 않음
- Inception + Depthwise Separable Convolution
논문의 워딩을 그대로 인용하면, 기존의 convolution과 Depthwise Separable Convolution은 서로 다른 spectrum을 가지고 있다고 설명
이를 풀어서 설명하면, 기존의 convolution(1x1)은 pixel 별로 filter가 적용
하지만 Depthwise Separable Convolution은 channel 별로 filter가 적용
이때 Inception은 3 x 3 convolution의 개수를 우리가 정할 수 있기 때문에 이 두 모델의 사이에 위치해있다고 설명
따라서, 저자들은 Inception과 Depthwise Separable Convolution을 합쳐 두 개의 장점을 모두 활용하고자 함
3. Model Architecture

모델의 전체적인 구조는 다음과 같다
특이사항으로는 총 34개의 convolution이 사용되었으며, 총 14개의 모듈로 구성
이때 1번과 마지막 모듈을 제외하고는 skip connection이 사용되었음
학습에 활용된 hyperparameter는 다음과 같다
ImageNet
SGD : momentum 0.9, learning rate 0.045
learning rate decay : 2 epoch 마다 0.94 비율로 감소
JFT
RMSProp : momentum 0.9, learning rate 0.001
learning rate decay : 3,000,000 samples 마다 0.9 비율로 감소
4. Experiment

ImageNet 데이터에 대한 결과
Xception이 다른 모델보다 가장 성능이 좋은 것을 확인할 수 있다

JFT 데이터에 대한 결과
이때 FC layer를 적용한 모델이 있고, 그렇지 않은 모델이 있는데 이는 마지막 Logistic Regression 이전에 위치

다음 그래프는 각 데이터에 대해서 step 마다 정확도 증가 추세를 그린 그래프이다
2, 3번째 그래프는 각각 FC layer가 있을 때와 없을 때를 비교한 것인데 FC layer가 있을 때 더 정확도가 높다

이는 parameter의 수와 속도를 비교한 표
xception이 속도와 parameter 모두 더 적은 모습을 볼 수 있다

해당 그래프는 skip connection의 유무에 따른 성능 변화를 보인 그래프
skip connection을 적용했을 때 훨씬 더 좋은 정확도를 보인다

이는 depthwise와 pointwise 사이에 활성화 함수에 따른 정확도 그래프
ReLU를 사용했을 때가 가장 낮고, 그 다음으로 ELU, 활성화 함수를 아예 사용하지 않았을 때 가장 성능이 좋다
이는 기존의 Depthwise Separable Convolution가 활성화 함수를 사용하지 않았는데, 이와 관련이 있는 것으로 추측
5. Contribution
Inception을 Depthwise Separable Convolution으로 대체할 것을 제안
Inception V3와 유사한 매개변수 수를 가진 새로운 아키텍처인 'Xception'을 제시
+ Comment
해당 논문을 보면, 저자들이 Inception을 얼마나 잘 이해하고 이를 활용하려 하였는지가 느껴진다
연구는 완전히 새로운 개념만을 생성해내는 것이 아니라 기존에 존재하던 것을 적절히 잘 융합하는 것도 중요하다는 것을 다시 한 번 느끼게 해주는 논문이였다



