MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce tw
arxiv.org
0. 핵심 요약
Mobile과 Embedded에 대해 효율적인 모델인 MobileNet을 제안
2개의 주요 hyper-parameter를 통해 latency, accuracy 간의 trade off를 효율적으로 해결
1. BackGround
- 기존 연구 방향
1. Compressing pretrained network
해당 방법은 network의 구조를 새롭게 생성하는 것이 아닌 기존에 있었던 모델을 어떻게 효율적으로 만들 수 있을 지를 고민한 것
예시로는 hashing, pruning, vector quantization, Huffman coding, distillation 등이 존재
해당 논문에서는 해당 방식은 전혀 사용하지 않았으며, 오히려 이를 사용하였을 때 효율이 그닥 좋지 않았다고 언급
2. Training small networks
이는 모델의 크기 자체를 감소시켜 모델의 효율성을 올리는 방법
MobileNet이 채택한 방법이며, 예시로는 Xception, SqueezeNet 등이 존재
기존의 방식과 해당 논문에서의 다른 점은 기존에는 단순히 모델의 크기에만 초점을 맞추어 모델을 개발하였다 함
따라서 MobileNet은 단순히 모델의 크기만이 아닌 모델의 속도 역시 고려하여 모델을 생성하였다고 함
2. 논문 핵심 내용
- Depthwise Separable Convolution
이는 기존의 Convolution을 2 단계로 구분하여 convolution을 구성한 것으로, 대략적인 설명은 이전 논문 리뷰를 참고
Xception: Deep Learning with Depthwise Separable Convolutions(Xception) Review
0. 핵심 요약 Inception에서 기존에 사용되었던 regular convolution을 depthwise convolution으로 대체한 모델인 Xception 제안 이는 Inception V3보다 파라미터의 수가 더 적어 효율적이면서 동시에 성능도 뛰어남 1
rltjq09.tistory.com
해당 논문에서는 computational cost을 줄이는 것이 가장 큰 목표였기 때문에 기존의 convolution과 depthwise separable convolution의 computational cost를 비교
Standard Convolution

이는 기존의 Convolution이며, 입력, 출력, kernel을 다음과 같이 표현
입력 : $D_F \times D_F \times M$
출력 : $D_G \times D_G \times N$
kernel : $D_K \times D_K \times M \times N$
이때, $D$는 각 이미지에 대한 해상도를 의미하며, $M$과 $N$은 각각 channel의 수를 의미
이를 활용하여 합성곱을 식으로 표현하면 다음과 같다
$G_{k,l,n} = \sum_{i,j,m} K _{i,j,m,n} \cdot F_{k+i-1, l+j-1,m}$
이는 쉽게 설명해 하나의 필터가 입력의 모든 채널을 돌아가면서 행렬곱을 수행하는 것
이에 대한 computational cost는 다음과 같다
$D_K \cdot D_K \cdot M \cdot N \cdot D_F \cdot D_F$
이는 곧 각각에 대해 배수만큼 cost가 소요된다는 것을 의미한다
Depthwise separable Convolution


해당 convolution의 핵심은 각 입력 채널마다 1개의 filter가 존재한다는 것
즉, 이를 식으로 표현하면 다음과 같이 표현할 수 있음
$\hat{G}_{k,l,n} = \sum_{i,j} \hat{K}_{i,j,m} \cdot F_{k+i-1, l+j-1, m}$
해당 식이 위의 식과 다른 점은 filter가 모든 channel에 적용되는 것이 아닌 동일 위치에 있는 channel에만 적용된다는 것
이에 대한 computational cost는 다음과 같다
$D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F$
이는 depthwise convolution과 pointwise convolution의 cost를 합한 것
standard convolution 대비 cost의 이득은 ${1 \over N} + {1 \over {D^2_K}}$
해당 모델에서는 3 x 3 depthwise separable convolution을 사용했는데, 이는 기존의 convolution에 대해 약 8~9배 더 적은 cost를 보이면서 동시에 거의 동일한 성능을 보임
그림으로 표현하면 다음과 같다

- 2 hyper-parameter
1. Width Multiplier
각 layer 별로 network를 더 얇게 만들어주는 hyper parameter
$\alpha$ 로 표현하며, 이를 사용하면 기존의 $M, N$ 이였던 channels을 $\alpha M, \alpha N$ 으로 변형
$\alpha \in (0,1]$ 이며 이를 사용하게 되면 cost가 감소하고 parameter 수가 감소한다는 장점이 존재
이는 MobileNet 뿐만 아니라 다른 모델에 사용해도 accuracy, size, latency 간의 trade off 에 유용
2. Resolution Mulitplier
입력 이미지 혹은 각 layer의 해상도를 조절하는 hyper parameter
$\rho$ 로 표현하며, 이 역시 $\rho \in (0,1]$ 이다
이미지 해상도의 범위는 224, 192, 160, 128
3. Model Architecture

이는 기본 MobileNet의 구조
추후에 Shallow MobileNet이 등장하게 되는데, 이는 14 x 14 x 512 filter를 5개 제거한 모델

이는 각 layer가 모델에서 차지하는 비율을 의미하며, conv 1 x 1이 parameter 수 대비 많은 computational cost를 차지하는 것을 볼 수 있음
4. Experiment

이는 Standard Convolution을 활용한 MobileNet과 아닌 MobileNet을 비교한 표
정확도는 약 1%만 하락하였지만, 이에 비해 parameter 수는 매우 많이 감소한 것을 볼 수 있다
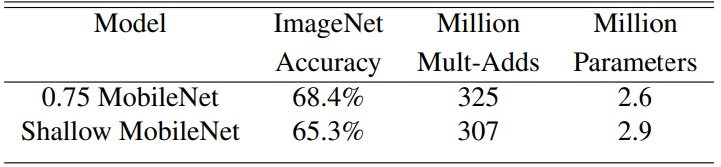
이는 위에서 언급한 Shallow 모델과 비교한 것인데, 해당 결과가 시사하는 바로는 깊이를 줄이는 것 보다 넓이를 줄이는 것이 더 정확도 감소율이 적었다는 것을 보여줌


왼쪽의 표는 width multiplier 값을 변경해가면서 성능을 비교한 표
이는 $\alpha$ 값을 감소할수록 정확도 역시 같이 부드럽게 감소하는 것을 보여줌
오른쪽 표는 resolution mulitplier 값을 변경해가면서 성능을 비교한 표
이도 왼쪽의 표와 유사한 결과를 보임
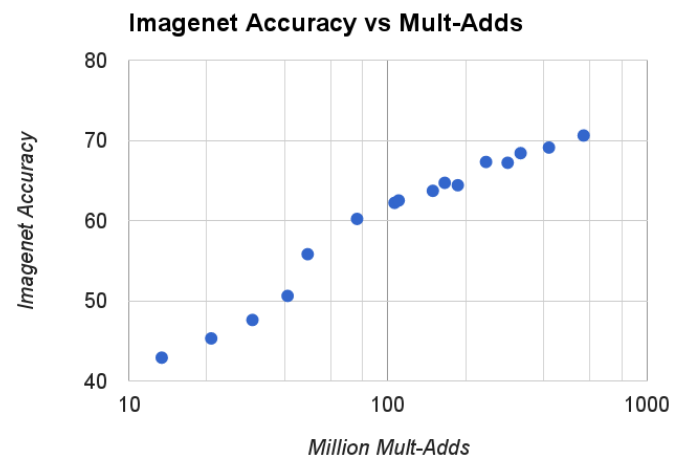

이는 두 hyper parameter 를 변경하면서 생성한 16가지의 모델들에 대해 정확도와 cost, parameter의 값을 그린 그래프
선형적으로 증가 혹은 감소하는 것을 볼 수 있다
이외에도 해당 논문에서는 MobileNet이 다양한 task에 적용될 수 있다는 점을 강조하면서 여러 task에 대해 적용한 결과를 볼 수 있다
이는 논문을 통해 직접 확인해보는 것을 추천한다
5. Contribution
Depthwise Separable Convolution을 기반으로 한 'MobileNets'라는 새로운 모델 아키텍처를 제안
width multiplier와 resolution multiplier를 사용하여 size와 latency을 줄이면서 합리적인 Accuracy를 희생하여 더 작고 빠른 MobileNets를 구축하는 방법을 시연
+ Comment
MobileNet은 한 때 경량화 모델로써 굉장히 많이 활용되었고, 현재에도 많은 버전 업그레이드를 통해 꾸준히 나오는 모델이다
depthwise separable convolution이라는 매우 단순한 아이디어로 많은 효율을 끌어올렸다는 것이 특징이다



