Fully Convolutional Networks for Semantic Segmentation(FCN)(2014) Review
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build
arxiv.org
0. 핵심 요약
Fully Convolutional Networks를 통해 임의의 입력 size를 받아 그에 맞는 output을 효과적으로 출력하도록 함
classification model을 fully convolutional과 결합한 후 fine-tuning을 하여 segmentation에 적용
1. BackGround
- 기존 Convolution Network의 구조
이전의 Classificaiton 논문들을 보면 알겠지만 모두 마지막 예측 부분에서 class score를 계산하기 위해 fully connected layer를 사용하는 것을 볼 수 있다

하지만, Segmentation 같은 경우에는 모든 pixel 마다 class가 결정되어 있어서 이와 같은 구조로는 절대 값을 구할 수가 없을 것이다
따라서, 해당 논문은 기존 Classfication의 좋은 능력인 feature extraction 능력은 사용하면서 이를 적절히 segmentation에 적용하기 위해 fully connected layer를 fully convolutional layer로 변경하고자 한다
논문에서는 크게 AlexNet, VGG, GoogLeNet을 사용했는데, 각각에 대한 설명은 이전 논문 리뷰를 참고
ImageNet Classification with Deep Convolutional Neural Networks(AlexNet) Review
ImageNet Classification with Deep Convolutional Neural Networks Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider th
rltjq09.tistory.com
Very Deep Convolutional Networks For Large-Scale Image Recognition(VGG) Review
Very Deep Convolutional Networks for Large-Scale Image Recognition In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of net
rltjq09.tistory.com
Going deeper with convolutions(GoogLeNet) Review
Going Deeper with Convolutions We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Cha
rltjq09.tistory.com
2. 논문 핵심 내용
- FCN
해당 논문의 목표는 위에서 말한 것 처럼 classification 모델을 segmentation에 적절하게 적용하는 것이다
이러한 과정에 있어서 논문 저자들은 다음과 같은 문제를 해결하였다
1. output 형식
가장 크게 바뀐 점은 바로 출력 형식이다
위에서 말했듯이 segmentation에서 가장 중요한 것은 출력이 입력 image와 동일하게 나와야한다는 것이다
이를 하기 위해서는 upsampling이 가능해야 한다는 가장 큰 걸림돌이 존재한다
논문에서는 해당 문제를 위해 여러가지 방법을 사용해보았다
가장 먼저 적용한 방식은 shift-and-stitch 방식이다
이는 예전부터 upsampling에서 사용되어져 오던 방식이지만, 계산 비용이 너무 많이 든다는 단점이 있었다
그 다음으로 생각한 방식은 보간 방법이다
최종적으로 이 방법을 채택하였는데, 이때 단순히 보간을 하는 것이 아닌 deconvolution 개념을 사용해 보간을 parameter화 하여 학습을 하게 하였다
이때 deconvolution이란 기존 convolution은 크기를 줄였다면, 이는 반대로 크기를 키우게 된다

해당 이미지를 보면, upsampling을 하게 되는데 중간에 학습이 가능한 parameter를 추가하여 이를 학습하고자 한 것이다
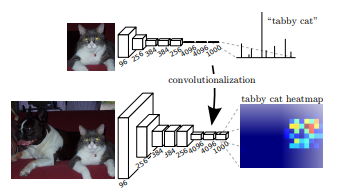
최종적으로 FCN은 이러한 upsampling과 fully convolution을 통해 다음과 같은 heatmap을 생성할 수 있게 된
2. 학습 방식
논문에서는 이를 어떻게 학습할 지도 많은 실험을 진행하였다
저자들이 선택할 수 있었던 방식으로는 patchwise 방식과 full-image 방식이 있었는데 이중 full-image 방식을 채택하였다

해당 그래프를 보게 되면 patch 단위로 sampling을 하는 것보다 full-image를 사용하는게 loss가 감소하는 속도가 더 빠른 것을 볼 수 있다
이러한 이유로 논문은 full-image를 한번에 학습하는 방식을 사용한다
3. loss function
기존 classification의 loss function은 softmax 과 log likelihood 를 같이 사용하는 방식이였다
하지만, segmentation은 pixel 별로 loss가 계산되어야 하는데, 기존 classification처럼 loss를 계산하게 되면 한 이미지마다 모든 pixel에 동일한 gradient가 전달되게 된다
이는 곧 학습이 전혀 이상한 방향으로 흘러가게 되는 것이다
논문에서는 이를 방지하기 위해 최종 output을 class 개수 + 1(배경) 개로 channel 개수를 설정하였다
그런 뒤, pixel 별로 multinomial logistic loss 를 적용하여 pixel 별 계산이 가능하도록 하였다
- Skip Connection
이는 ResNet을 읽어본 사람이라면 매우 친숙한 개념일 것이다
FCN에서는 이 Skip Connection을 upsampling 시에 사용하였다
upsampling이 비록 파라미터를 통해 학습이 진행된다고는 하지만 여전히 coarse한 정보들만을 담고 있는 것은 변함이 없다
논문에서는 이러한 문제를 해결하기 위해 skip connection으로 앞단의 fine한 정보들을 추가해주기로 결정한다
segmentation은 global한 정보를 통해 class를 예측하고, local 한 정보를 통해 region을 예측한다
이 두가지를 동시에 수행하기 위해서는 결국 2가지 정보가 모두 필요한데 이때 필요한 것이 바로 skip connection 인 것이다

위 그림을 보면 숫자가 작아질수록 더 많은 skip connection을 지난 것인데 map이 점점 더 세밀해지는 것을 볼 수 있다
3. Model Architecture
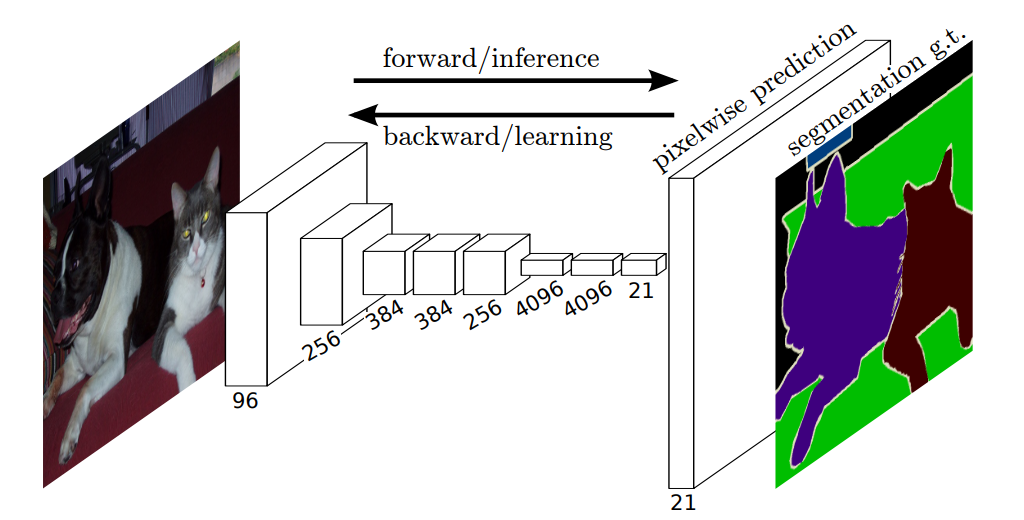
해당 이미지는 FCN을 매우 단순하게 표현한 그림이다

해당 이미지가 FCN의 전체적인 Architecture를 더욱 자세하 나타낸 모습이다
이를 간단히 설명하자면, 우선 이미지가 들어와 BackBone 모델을 지나면서 feature 를 생성한다
그 이후, 마지막 layer에서 앞서 설명한 upsampling 방식을 통해 최종 예측 output을 생성한다
이때, 방식이 총 3가지가 있는데, 우선 32s는 마지막 layer에 stride 32를 적용해서 곧바로 output을 생성하는 것이다
16s는 마지막 layer에 upsampling을 진행하여 바로 이전 layer와 형상을 맞추고 두 feature를 더해준다
그런 다음 더한 feature 로 다시 upsampling을 수행해 output을 생성한다
마지막 8s 역시 똑같은 과정을 한번 더 수행하고 output을 만든다
이처럼, 점점 더 image와 가까운 layer을 더할 때마다 세밀해지는 이유는 앞단의 layer들은 직접적인 image의 정보를 많이 담고 있기 때문에 더 세밀한 정보를 파악할 수 있기 때문이다
각종 hyper parameter
SGD, momentum 0.9, weight decay $2^{-4}$
learning rate $10^{-4}$
batch size 20 (총 20개 image)
4. Experiment

해당 표는 upsampling 시 parameter로 학습한 것이 아니라 단순 보간을 실시했을 때의 결과이다
VGG16이 가장 결과가 좋았는데, 해당 수치는 이미 그 당시 SOTA를 달성하는 기록이였다고 한다

이는 새로운 upsampling 방식을 도입하고, skip connection 별 성능을 비교한 표이다
역시 가장 세밀한 정보를 담은 모델이 가장 좋은 성능을 보이고 있다



다양한 데이터에 실험을 해봤을 때 역시 가장 우수한 성능을 보이고 있다

실제로 masking map을 확인해봐도 다른 모델보다 훨씬 우수한 것을 볼 수 있다
5. Contribution
Fully Convolutional Network 는 Classification Network를 Segmenation으로 확장
+ Comment
Segmentation에 시초와 같은 논문이라고 생각한다
지금이야 당연하게 channel 별로 class 확률을 확인하지만 이 당시에는 이러한 개념이 없었는데 이를 생각해낸게 대단하다고 생각이 든다
지금은 SAM과 같은 모델이 너무나도 정확한 Segmentation을 해주지만 SAM을 이해하기 위해선 역시 이러한 논문들도 매우 중요하다고 생각한