ImageNet Classification with Deep Convolutional Neural Networks
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
0. 핵심 요약
- AlexNet이라는 새로운 모델을 제시하였으며, CNN의 가능성을 보여준 논문
- 현재에는 많이 쓰이는 ReLU, Dropout 등을 적용하여 성능을 내보임
- CNN의 발전의 시초라고 볼 수 있음
1. Background
- DataSet
AlexNet은 ImageNet 데이터를 통해 학습
ImageNet 데이터셋은 약 1500만개의 이미지가 존재하고, 22000 클래스가 존재
해당 데이터는 웹 상에서 수집되었고, Amazon's Mechanical Turk crowd-sourcing tool에서 사람이 직접 labeling 수행
https://image-net.org/
ImageNet
Mar 11 2021. ImageNet website update.
image-net.org
해당 데이터셋을 활용한 Classification 대회가 존재하는데, 이는 ILSVRC(ImageNet Large-Scale Visual Recognition Competition) 이며 AlexNet은 2010, 2012 년도의 대회의 데이터를 통해 성능을 검증
ImageNet 데이터는 모든 이미지의 해상도가 통일되어있지 않음
하지만 모델은 고정된 이미지의 크기를 요구하기 때문에 이를 256 x 256으로 조정
조정하는 방법은 양변 중 짧은 부분을 256에 맞춰 scaling을 한 후, centercrop을 통해 조정
이후, 모든 픽셀 값의 평균을 빼주는 전처리 작업을 진행
- Stationarity of Statistics
Stationarity란? → 데이터들이 시간에 관계 없이 데이터의 확률 분포는 일정하다는 가정
이를 이미지에 적용해보면, 데이터가 위치에 관계 없이 분포가 일정하다는 것

해당 이미지를 보면, 서로 다른 두 사람이지만 입 모양은 비슷한 것을 볼 수 있다
즉, 위치는 다르지만 모양의 분포는 유사할 수 있다는 것
이를 Convolution 연산에 적용해보면, Convolution 연산은 동일한 필터를 이동시키면서 이미지의 특징을 파악한다
따라서 각각 필터마다 어떤 필터는 입 모양을 학습하고, 어떤 필터는 눈 모양을 학습하여 인식하게 된다
이는 입이 여러 개라고 해서 여러 필터를 만들 필요가 없고 하나의 필터로 모든 입을 인식할 수 있다는 의미가 된다
이러한 성질을 활용하고자 하는 것이 CNN의 핵심이다
- Locality of pixel dependencies
이는 ' 이미지는 작은 특징들로 구성되어 있기 때문에 픽셀의 종속성은 특징이 있는 작은 지역으로 한정된다' 라는 의미
쉽게 설명하면, 이미지에서 특정 부분의 특징을 결정하는 것은 해당 픽셀의 주변 부분이라는 것이다CNN은 주로 3 x 3 필터를 사용, 중심 픽셀의 바로 주변 픽셀의 정보를 활용하는데 해당 특징으로 인해 이러한 필터가 효과적으로 작용하는 것이다이러한 성질 역시 CNN이 효과적으로 작용하는 이유 중 하나이며, Parameter의 개수를 줄일 수 있는 또 다른 이유이다
더욱 자세한 내용은 아래의 블로그를 참고https://seongkyun.github.io/study/2019/10/27/cnn_stationarity/
CNN의 stationarity와 locality · Seongkyun Han's blog
위의 이미지와 동일하지만 눈, 코 특징이 사진의 왼쪽 상단에 존재한다는 것만 다르다. 위 이미지와 특징의 위치가 서로 다른데, 사람 몸이라는 동일한 출력값을 내놓기에 역시 translation invariant
seongkyun.github.io
- Lateral inhibition(측면 억제)

위의 그림을 보게 되면, 흰색 선 사이에 회색 동그라미가 존재하는 것처럼 보이게 됨
이는 우리의 눈이 주변의 검정색 네모에 영향을 받아 착시현상을 일으키는 것
AlexNet은 이러한 개념을 모델에 추가, 더욱 자세한 설명은 아래에서 설명
2. 논문 핵심 내용
1. ReLU Nonlinearity
현재에는 표준으로 사용하는 활성화 함수이지만, 당시에는 Sigmoind 나 tanh 가 대세를 이끌고 있었다
하지만 위의 함수들은 딥러닝의 핵심 기술인 Gradient Descent를 계산하는 데에 있어 시간이 오래 걸린다는 단점 존재

위의 그래프는 논문에서 제시한 학습에 걸리는 시간에 따른 그래프이며, 실선은 ReLU, 점선은 tanh
똑같이 loss가 0.25까지 도달하는 epoch의 수를 측정했을 때, ReLU는 약 7 epcoh, tanh는 약 37 epoch
또한, ReLU를 사용함으로써 모델의 문제점인 overfitting을 방지하는 효과를 얻을 수 있었다고 함
2. Training on Multiple GPUs
당시에는 GPU가 지금처럼 발달한 시기가 아니였음
따라서 GPU 메모리를 효율적으로 활용하는 기술이 필요, Alexnet에서는 2개의 GPU를 사용하여 학습하는 방법을 채택
GPU는 병렬화 작업에 최적화되어 있으며, 이는 메인 메모리를 거치지 않고 바로 GPU 간의 읽고 쓰기가 가능함
해당 병렬화 작업 시에는 filter의 절반을 각각 GPU에 입력하는데, 이는 모델의 특정 부분에서 수행
layer 3은 layer 2의 모든 filter가 입력되지만 layer 4에서는 layer 3에서 본인의 GPU에 있는 filter만 전달 받음
아래의 모델 구조 그림을 보면 이해에 용이
3. Local Response Normalization
모델의 입력에 대해서 정규화를 수행하는 것은 모델의 학습에 있어서 많은 도움이 됨
따라서 AlexNet 역시 정규화를 수행하는데, 이때 위에서 설명한 Lateral inhibition 개념을 추가

다음 수식은 정규화 과정을 설명한 수식

: 이미지에서 x, y의 위치에 있는 픽셀이 filter i에 의해 계산된 결과 값
N : layer에 있는 모든 filter의 개수
n : i번째 filter의 주변 filter의 개수
위의 수식을 설명하면, '특정 filter의 주변 n개의 filter에 대해 계산된 값들을 반영하자' 입니다
여기에서 k, alpha, beta, n은 모두 hyper-parameter이며 validation set을 통해 조정
즉, 해당 필터를 통해 계산된 값을 결정할 때 해당 필터의 값만 계산하는 것이 아닌 주변 필터도 활용하겠다는 아이디어
이는 lateral inhibition에서 주변에 의해 해당 위치의 값이 결정되는 것에서 착안
4. Overlapping Pooling
우리가 흔히 알고 있는 Max Pooling 혹은 Mean Average Pooling은 필터 크기와 stride 크기를 동일하게 유지하여 필터가 서로 겹치지 않도록 하는 것이 일반적
하지만 AlexNet에서는 이를 의도적으로 겹치도록 하여 더 좋은 성능을 발휘했다고 함
예를 들어, 기존에는 filter size = 2, stride = 2였지만 이를 filter size = 2, stride = 3으로 하여 수행

5. Reduce Overfitting
- Data Augmentation
AlexNet은 Overfitting의 문제를 많이 겪었는데, 이를 해결하기 위해 Augmentation 기법을 총 2가지를 적용
1. Horizontal reflections
이미지를 수평으로 뒤집는 것
ImageNet에서 전처리를 통해 256 x 256으로 변환하였는데, 여기에서 다시 224 x 224를 추출한 다음 horizontal reflections을 적용
2. PCA를 통한 RGB pixel 값 조정
RGB 픽셀에 대해 PCA를 수행하여 고유값과 고유벡터를 구함
그런 뒤, 평균이 0이고 표준편차가 0.1인 정규분포에서 랜덤하게 값을 추출한 뒤 해당 값과 고유값을 곱한 값을 픽셀 값에 적용
이는 조명이나 밝기와 같은 부분에 있어서 항상성을 유지하기 위한 방법으로 활용
- Dropout
현재에는 매우 흔하게 사용되는 기법으로, 딥러닝에서 overfitting 방지와 동시에 ensemble 효과를 얻을 수 있는 기법

위 그림에서 보듯이 한 layer에서 모든 뉴런을 활용하는 것이 아닌 확률적으로 뉴런을 선택해서 모델에 적용하는 것
이는 매 epoch 마다 선택되는 뉴런이 달라지므로 앙상블 효과와 overfitting 방지 효과를 동시에 누릴 수 있음
AlexNet은 해당 비율을 0.5로 설정했으며, inference 시에는 모든 뉴런을 사용하는 대신 최종 결과 값에 0.5를 곱하여 출력하였음
3. Model Architecture

4. Experiment

위의 표는 ILSVRC-2010 대회의 결과로, 기존의 성능에서 약 8% 더 좋은 성능을 기록
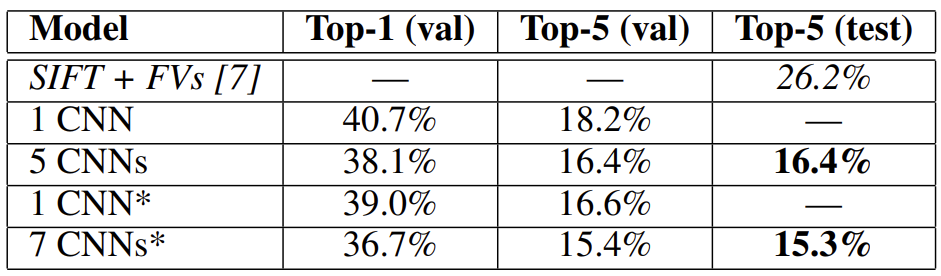
해당 표는 ILSVRC-2012 대회의 결과로, 기존의 성능에 비교해 많은 향상이 있었으며, layer가 많아질수록 더 좋은 성능을 보이는 것을 볼 수 있음

해당 결과는 GPU 별로 필터가 어떤 경향을 띄는 지를 확인한 것
GPU를 나눠서 학습하였기 때문에 위의 GPU는 색을 보지 않고, 아래의 GPU는 색을 주로 파악하면서 서로 다른 역할을 수행했다는 것을 확인할 수 있었음

해당 그림은 최종 5개의 예측값을 확인해본 결과, 오답이라 하더라도 그럴만한 이유가 있었다는 것을 보여줌
5. Contribution
해당 연구를 통해 깊은 CNN이 지도 학습에서 높은 결과를 낼 수 있다는 것을 확인
해당 신경망에서 층을 1개라도 지우게 되면 성능이 떨어짐, 이는 깊이가 성능에 매우 큰 영향을 준다는 것을 보여줌
비지도학습은 도움이 될 것 같았으나 사용하지 않았고, 충분한 컴퓨팅 파워가 있었다면 라벨링된 데이터를 모으는 것보다 신경망의 크기를 키웠을 것임
현재 신경망이 커지고 학습시간이 길어지고 있지만, 사람의 시각 시스템을 따라가기엔 많은 단계가 남아있다
+ Comment
AlexNet은 단연 현재의 AI 시대의 시초라고 볼 수 있다
물론 현재에는 전혀 쓰이지 않는 모델이지만 이가 있기에 현재의 모델들이 존재한다고 해도 과언이 아니다
딥러닝을 처음 접하는 사람들은 꼭 필수로 읽어야 하는 논문이라고 생각한다



