U-Net: Convolutional Networks for Biomedical Image Segmentation
There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated
arxiv.org
0. 핵심 요약
Architecture는 문맥을 파악하기 위한 contracting path와 symmetric expanding path로 구성
모든 학습은 end-to-end로 이루어지며, augmentation에 대한 학습 전략 제시
1. BackGround
- Dataset
ISBI, DIC와 같은 데이터셋을 사용하였다고 한다
이렇게 들으면 모두 생소한 데이터셋일텐데, 그러한 이유는 U-Net 자체가 일반적인 segmentation을 위한 모델이 아닌 biomedical에 대한 데이터를 위해 만들어진 모델이기 때문에 모두 세포와 관련된 이미지 데이터들이다
따라서, 뒤에 나오는 모든 Experiment나 image들은 모두 세포 이미지라는 것을 인지해두길 바란다
- 기존 Segmentation 기법
기존에는 역시 Classification에서 Convolutional Network가 많이 사용되었다
이를 Segmentation에 적용하기 위해 sliding window 기법을 이용해 image를 지나가면서 patch를 생성
생성된 patch에 대해 network를 적용하여 segmentation을 수행하였음
이렇게 하면 data가 많아진다는 장점을 얻을 수 있지만, 중복되는 부분들 때문에 일반성이 떨어진다는 단점이 있다
또한, 추가적으로 patch별로 수행하기 때문에 속도가 매우 느려지고, localization과 context 간의 trade-off가 발생
localization과 context 간의 trade-off가 발생하는 이유는 다음과 같다
localization과 같은 경우는 이미지 내에서 특정 부분을 보고 판단해야 더 정확도가 많이 올라가는 편이고, context 같은 경우는 이미지 전체를 보고 문맥을 파악해야 하는 것이기 때문이다
그래서 patch 별로 수행하면 context를 볼 수가 없게 되는 것이다
- FCN
U-Net은 FCN에서 영감을 받아 제작되었다고 한다
실제로 upsampling 기법이나, crop and concat 하는 것이 FCN과 매우 유사하다
해당 모델에 대한 자세한 내용은 이전 리뷰를 참고
Fully Convolutional Networks for Semantic Segmentation(FCN) Review
Fully Convolutional Networks for Semantic Segmentation Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-ar
rltjq09.tistory.com
2. 논문 핵심 내용
- Overlap-tile strategy

U-Net은 세포 데이터를 segmentation 하는 것이 목적이다
위의 이미지에서 보이는 것처럼 일반적인 사진은 아닌 것을 알 수 있다
하지만, 세포 이미지는 다량으로 존재하는 데이터가 아니기 때문에 data augmentation은 필수적인 부분이였다
따라서 U-Net에서는 한 이미지에서 여러 부분을 crop 해서 data로 사용하였는데, 위 이미지를 설명하면 다음과 같다
U-Net은 노란색 부분을 segmentation 하기 위해서는 파란색 부분 만큼의 입력이 필요하다
하지만, 이미지의 외곽 부분은 오른쪽 이미지처럼 특정 부분이 존재하지 않는 경우가 있다
이럴때 U-Net에서는 이를 해결하기 위해 mirroring 기법을 사용하였다
이는 말 그대로 기존의 있는 데이터를 거울에 반사하듯이 반사하여 빈 부분을 채워주는 것이다
이러한 기법을 활용해서 데이터를 더 많이 확보하였다고 한다
- loss function
U-Net이 예측하고자 하는 것은 이미지에서 세포인지(1) 아닌지(0) 이다
즉, 이는 이진분류이다
따라서, 마지막 출력이 각 픽셀 별로 2차원을 가지고 있다
이러한 이유로 U-Net은 pixel 별 soft-max + croos entropy loss 를 채택한다
이는 쉽게 얘기해서 1은 더 1로 수렴하도록 만들고, 0은 더 0으로 수렴하도록 만드는 것이다
식으로 표현하면 다음과 같다
$E = \sum_{x \in \Omega} w(x) log(p_{l(x)}(x))$
이때, $l(x)$는 정답 label을 의미한다
위의 식에서 처음 보는 것이 등장하는 데, 이는 $w(x)$ 이며 해당 함수가 수행하는 역할은 다음과 같다
U-Net의 목표는 세포인 부분과 아닌 부분을 명확하게 구분하는 것이 중요하기 때문에 두 부분의 경계를 제대로 예측하는 것이 매우 중요하다
따라서, 경계 부분에 대해 이 부분이 더 중요하다는 가중치를 주는 함수(weight map)이라고 한다
이는 ground-truth 를 통해 미리 계산되며 식은 다음과 같다
$w(x) = w_c(x) + w_0 \cdot exp( -{(d_1(x) + d_2(x))^2 \over 2\sigma^2}$
해당 식은 morphology operations에 근거하여 만들어 졌다고 한다
이에 대한 자세한 설명은 아래 블로그를 참고
Mathematical morphology (모폴로지 연산)
Mathematical morphology (모폴로지)Thresholding에 의해 얻어진 binary image를 좀 더 가공하여 완성도를 높이기 위해서는 morphology를 이용한다. 가공의 의미는 noise나 너무 작은 feature들을 제거하는 것을 의
swprog.tistory.com
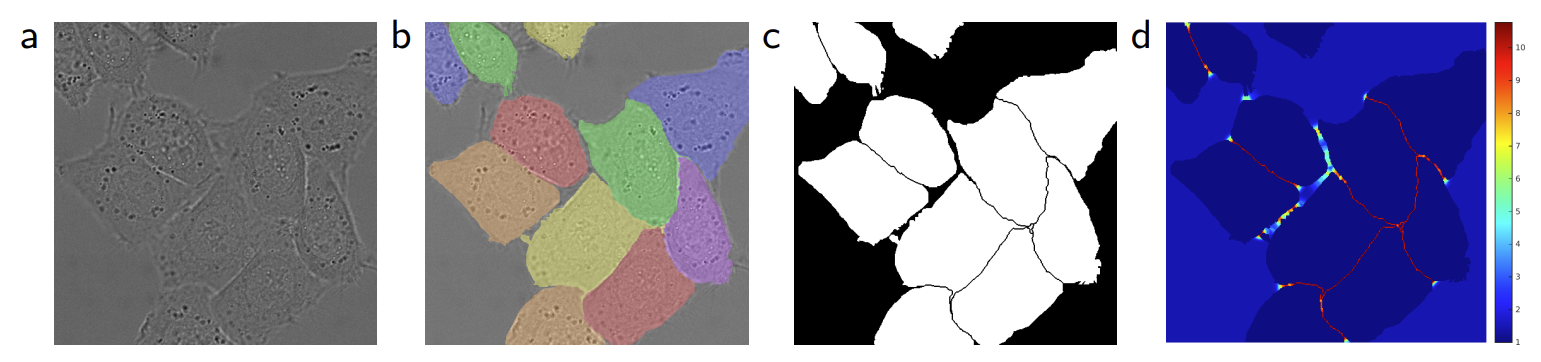
해당 이미지가 위의 weight map을 생성하는 과정이다
d를 보면 경계 부분에 가중치가 크게 부여되는 모습을 볼 수 있다
3. Model Architecture

위 그림은 U-Net의 아키텍처를 표현한 그림이다
위의 그림을 보면 왜 해당 모델의 이름이 U-Net인지를 알 수 있을 것이다
왼쪽 부분에 점점 해상도가 감소하는 부분이 context를 파악하는 contracting path이며, 오른쪽 upsampling이 되는 부분이 expansive path이다
위 그림에 자세하게 설명이 되어 있기 때문에 더욱 자세한 설명은 생략하도록 하겠다
학습은 SGD를 통해 이루어졌으며, momentum은 0.99를 사용했다
가중치 초기화는 가우시안 분포에서 평균은 0, 분산은 $\sqrt{2 / N}$ 인데, 이때 N은 입력되는 노드의 수이다
4. Experiment

세포 이미지에 대한 결과이기에 기존 결과들과는 달라 좀 생소하지만 warping error가 u-net이 가장 낮은 것을 볼 수 있다

또 다른 세포 데이터에도 적용해보았을 때 성능이 가장 좋았다
5. Contribution
U-net은 biomedical image segmentation에서 매우 좋은 성능을 달성
매우 적은 수의 labeling image만 필요로 하며, 매우 빠른 학습 속도
+ Comment
Segmentation 하면 가장 먼저 떠오르는 모델 중 하나가 U-Net이 아닐까 생각한다
비록 논문 작성 시에는 의료 데이터를 위한 모델이였지만 현재에 와서는 AutoEncoder와 같이 Encoder와 Decoder의 개념을 처음으로 보인 것이 아닐까 생각한다
논문 리뷰를 하나씩 해나갈 때마다 빨리 최신 논문을 리뷰해서 글을 올리고 싶다는 생각이 많이 든다
'논문 리뷰' 카테고리의 다른 글
| Deformable Convolutional Networks(DCN)(2017) Review (2) | 2024.02.08 |
|---|---|
| Mask R-CNN(2017) Review (1) | 2024.02.06 |
| Fully Convolutional Networks for Semantic Segmentation(FCN)(2014) Review (1) | 2024.02.02 |
| Feature Pyramid Networks for Object Detection(FPN)(2016) Review (1) | 2024.01.31 |
| You Only Look Once:Unified, Real-Time Object Detection(YOLO V1)(2015) Review (1) | 2024.01.29 |



